About
自Faster R-CNN后,基于深度学习的目标检测框架大致形成,且精度也较为不错。在这之后,围绕着对图像数据更深层次理解,以及根据现有结构进行改进成为了一个主流点。
Speed/accuracy trade-offs for modern convolutional object detectors
object detection in 20 years: a survey
IoU-uniform R-CNN: Breaking Through the Limitations of RPN
https://arxiv.org/pdf/1909.02466v2.pdf
R-FCN
Introduction
内容有参考:
Content
FPN
Introduction
Feature Pyramid Networks(FPN)考虑到了卷积神经网络中各个尺度特征图的作用,认为像Fast R-CNN和Faster R-CNN这样的目标检测网络只用了一个特征图去来做RoI 和搜寻proposal,不一定能很好地处理全部尺寸的物体,虽然这种方式是为了speed-acc之间的trade off。作者认为,网络越深层产出的特征图往往语义信息越高,但是位置信息比较模糊,对小目标检测来说不太好;浅层的特征图提取出来的特征都是比较低级的边缘,纹理信息,但是分辨率好,位置信息得到了保留,因此将这些特征图结合起来,充分利用到高层语义信息,同时也不丢掉位置信息,应当能很大程度上提高检测的精度和鲁棒性。
博客内容有参考:
Content
为了让各个尺寸的物体都能很好的检测到,以往的工作提出了图像金字塔,利用不同大小的图像尺寸进行滑窗,到了深度学习时代,直接通过神经网络输出的高层特征图,进行对应特征上的检测分类,之后考虑到尺度问题,开始挑选网络中产出的几个level的feature map,分别进行检测,然后合并筛选给出最后的结果。FPN认为,既然检测既需要高层的特征便于分类和统筹全局观念,又需要特征图具有一定的分辨率去定位物体的图像位置,那么应该想个办法将这两个重要信息结合起来。但是在网络的前向传播中,这两者是矛盾的,低层的特征图特征抽象度不够,高层的特征图物体分辨率过低。我想,作者应该是受到当时resnet等跳级连接和FCN,U-Net等语义分割模型的启发,通过下采样提取高级特征,上采样恢复尺度,同时侧级连接补充位置信息,然后在每个上采样的特征图上进行检测来覆盖到各个物体(这一点借鉴了SSD)。
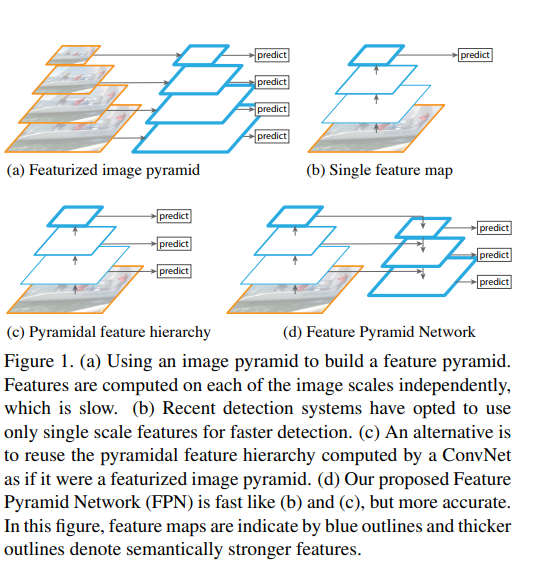
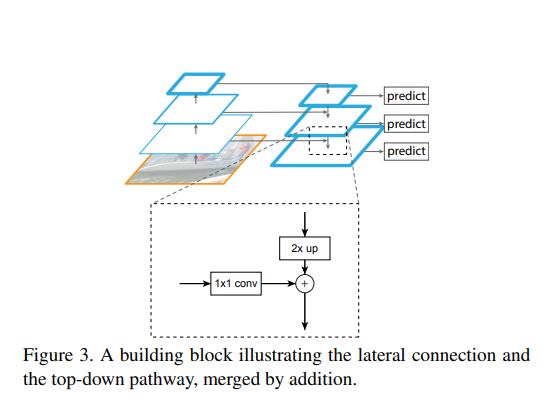
如果没有每个特征图的预测,乍看就是FCN的经典结构。不过FPN的侧重点是为了结合高级语义特征和位置信息,因此加了一些额外的卷积操作,让网络在梯度下降中去focus这一点。下采样过程属于正常的网络操作,上采样时每个特征图进行2倍放大(最近邻插值,非转置卷积),当然这个2倍是根据你的下采样倍数来的,一般都是2倍,然后侧向对应的不是直接加过来(FCN),也不是叠操作(U-Net),而且先用个卷积处理下采样的特征图,然后加在一起,最后再做个的卷积。的卷积是为了减少通道数(上采样的通道数是固定的),否则不能相加,同时我想可能也是去提取一下位置信息,的卷积是为了处理一下加在一起后的特征图的混叠效应,提取出两者的有用信息。
值得一提的是,作者在论文中也说了,按照解决问题的思想,这样的金字塔形式应当是最简单的,没有加入任何其他的复杂技巧,实验效果证明效果也足够好,简单又有效。
Simplicity is central to our design and we have found that our model is robust to many design choices. We have experimented with more sophisticated blocks (e.g., using multilayer residual blocks [16] as the connections) and observed marginally better results. Designing better connection modules is not the focus of this paper, so we opt for the simple design described above.
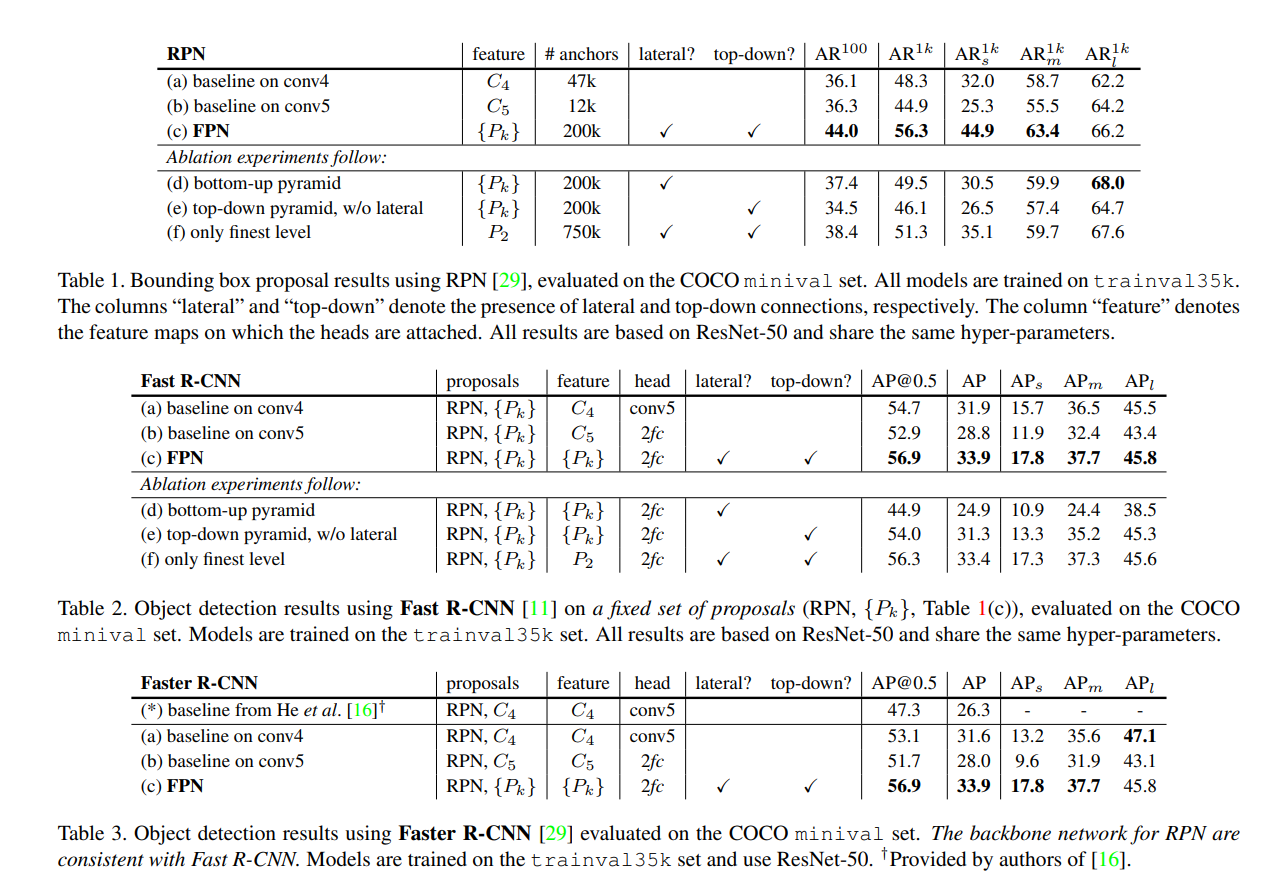
实验方面,FPN主要针对RPN和Fast R-CNN进行,通过ablation study论证了FPN结构的有效性,同时结构之间的各个部件都是必要的。其中 RPN 和 Fast RCNN 分别关注的是召回率和正检率,在这里对比的指标分别为 Average Recall(AR) 和 Average Precision(AP),分别对比了不同尺度物体检测情况。
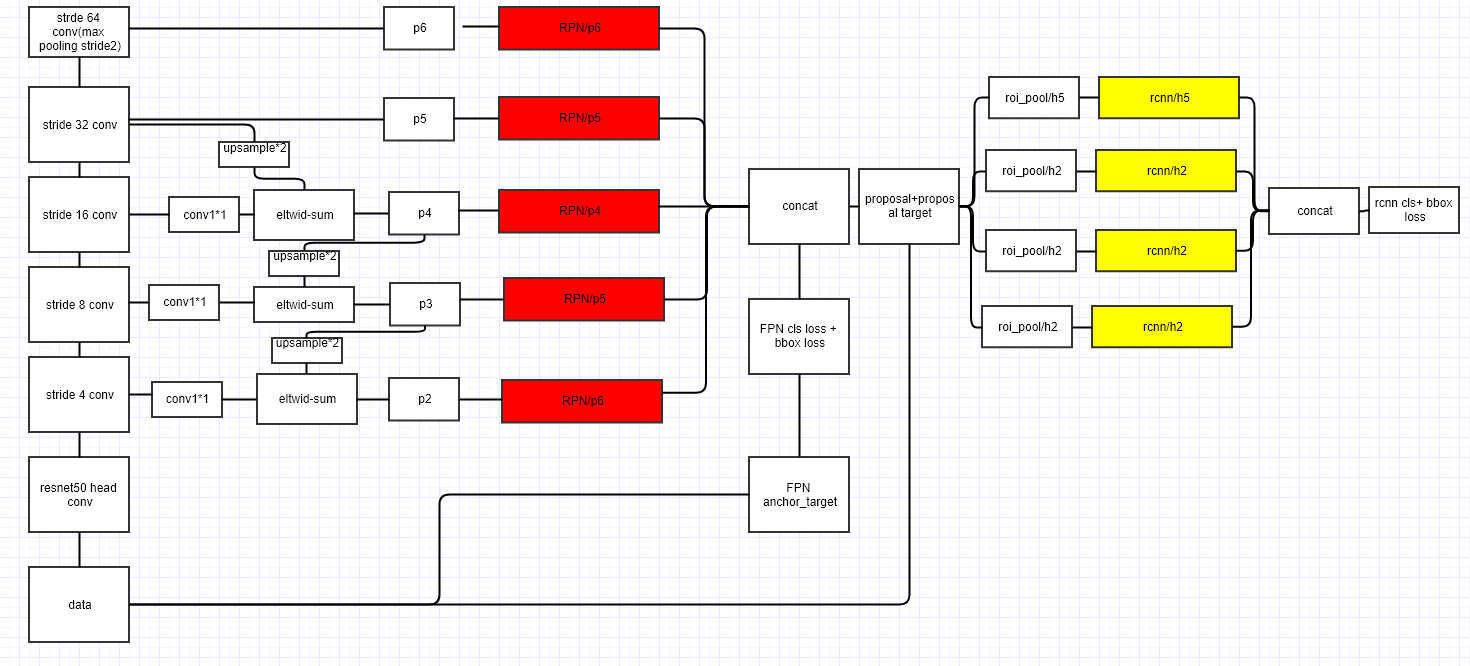
以resnet为例,不管第一次feature map的缩小(的卷积),用后面的。对RPN来说,只用了去生成预选框,然后利用pyramid of anchor去搜区域,由于FPN已经有了多尺度的作用,因此每个上采样的特征图中,会根据其特点设置一个固定size的anchor area,anchor aspect ratio还是保持[0.5, 1, 2]不变。为了照应到RPN中的512大小的anchor,FPN实验时多加了一个特征图(在上下采样2倍),对应的区域大小和特征图level分别是:,用代表上采样的特征图,便于区分下采样的。从设置里可以看出,大特征图里找小物体,小特征图里找大物体。
实验Fast R-CNN时,固定FPN+RPN提取的proposal结果,在其中也加入FPN分别在中找物体做RoI Pooling,一样的,对于大尺度的RoI就用小的特征图,小尺度的RoI就用大的特征图。为了安排每个RoI Pooling尺度对应的特征图,作者给出如下公式:
其中,224是ImageNet的标准输入尺寸,是基准值,代表最后一个特征图,分别代表RoI区域(RPN+FPN给的原图的proposal)的宽和高。假设RoI大小是,那么,就在特征图上找,做RoI Pooling。一般来说proposal大小不固定,所以应该取整处理。
因为resnet的Conv5也作为特征金字塔的一部分,而原先的Fast R-CNN和Faster R-CNN在RoI Pooling后面才接上Conv5继续提取特征,所以论文简单的加了两个1024维的fc层在分类器和回归器之前,代替一下原先Conv5的工作。
最后在加入FPN的Faster R-CNN中进行参数共享,检测精度也得到了一定的提升。具体实验结果直接看图,不再赘述。
Conclusion

FPN的贡献思想在于向上采样,融合了特征信息和位置信息,而且简洁有效。在这之后,何恺明率先利用FPN实现了Mask R-CNN,一统检测和实例分割,斩获马尔奖。现在FPN也被广泛使用,成为检测的必备组件(R-FCN由于自身设计缘故,无法加入FPN)。
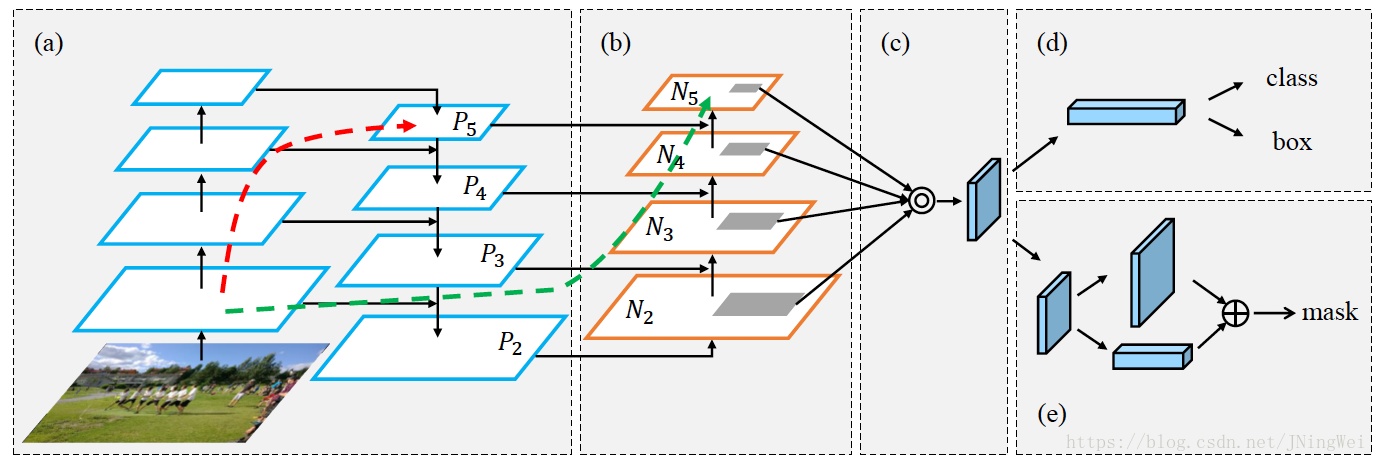
但是,FPN设计中的上采样和侧向连接,其实主要是给小目标检测提供了帮助,因为主要是引入位置信息,然后放大特征图(实验结果也说明小目标检测精度提升多)。对于大目标来说,顶层特征图的高级语义固然重要,位置信息肯定还是没有底层特征图的多的,因此可以对一开始网络产出的浅层特征图跳级连接到顶层特征图,类似下面的结构(PANet):
RetinaNet
https://zhuanlan.zhihu.com/p/133317452









