About
Faster R-CNN是目标检测领域中"two-stage"的代表性方法,其精度高,适应性强,兼具学术和工程价值。整个框架由于吸取了很多先前工作的经验,因此比较庞大,而且细节很多,因此需要认真研读下相关paper和Faster R-CNN的python代码。
在此之前,先贴上一位博主做的“The Modern History of Object Recognition — Infographic”,其中也包括了“one-stage"的方法,不过2017年以后的没再更新了。

R-CNN
Introduction
R-CNN(Rich feature hierarchies for accurate object detection and semantic segmentation)是将深度学习应用于目标检测的开山之作,以前传统的目标检测算法使用滑动窗口法依次判断所有的可能区域,在该文章中,采用selective search方法先预先提取一系列可能是物体的候选区域(foreground),之后将这些候选区域(proposals)整合成固定的大小(, 采用AlexNet)送到预训练的CNN模型上提取特征然后进行fine-tuning迁移学习,然后通过fc6和fc7层,得到了针对目标检测任务的特征向量,然后再过SVM二分类器得到物体的每个类别分数(至于为什么用了两层fc,不直接用三层fc得到softmax分数,Ross他也在论文中作了说明和实验,主要原因就是proposal的筛选更加严格点,mAP更高点),得到2K个左右proposal的所属类别之后再做非极大抑制(NMS),去掉那些多余的框,留下局部最优的建议框,然后根据这些剩下的框再去训练20个类别(针对pascal VOC数据)的regression器,最后终于得到图像中物体的种类和矩形框坐标信息。
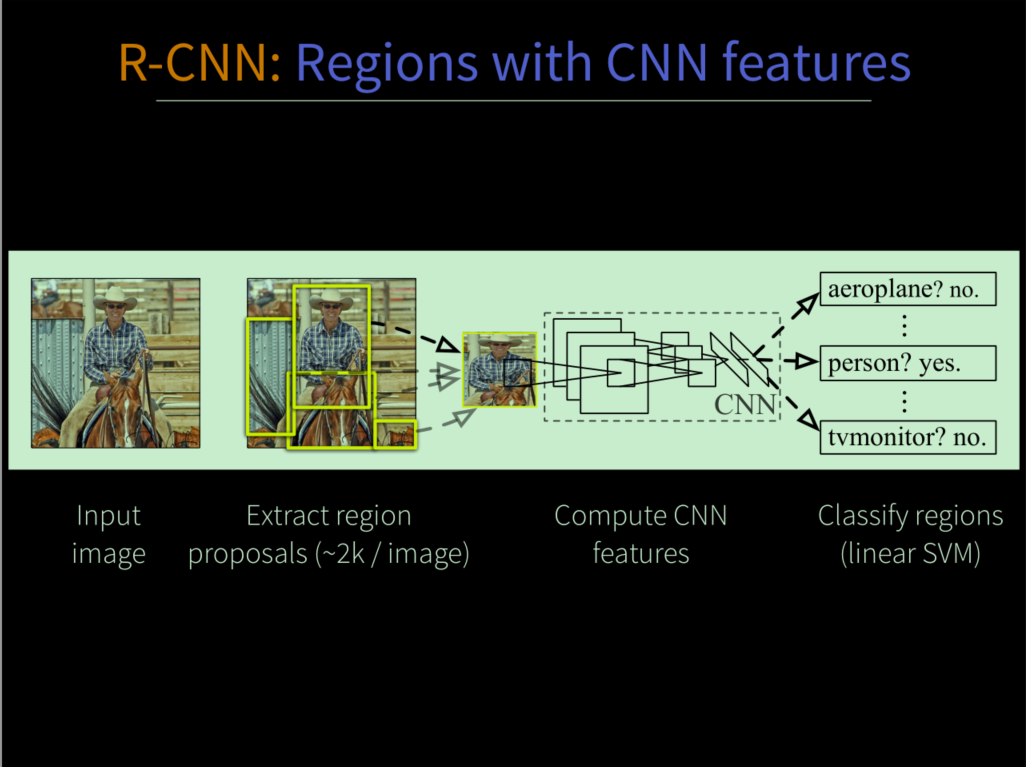
下面对一些重点内容进行分析,同时由于是object detection based CNN开篇,所以也顺便加上评价指标等细节。
评价指标IoU和AP
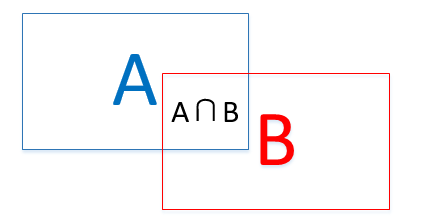
**IoU(insertion of union).**中文名为交并比,主要用来衡量框与框的重合程度,计算公式为
**AP(Average Precision)与mAP(mean Average Precision).**这是目标检测中常用的评价指标,AP代表每一类的检测精度,mAP代表所有类的整体检测精度,也就是所有类AP的平均值。AP一般是二分类问题的P-R曲线(precision-recall curve)与x轴围成的面积。
accuracy(准确率)=,预测对的样本/所有样本;
precision(精准率)=,预测对的正样本/预测出的正样本;
recall(召回率)=,预测对的正样本/真正的正样本;
如何绘制PR曲线?首先将样本按照置信度从大到小排列,然后设置一个从高到低的阈值,大于该阈值的才能认定为正样本,否则为负样本,在该阈值下就能得到一组(P,R)值,阈值设的越细,点对就越多,这样连接成线就得到了P-R曲线。
AP的计算一般是通过插值或者估算的方式进行的,并不是直接积分。
针对Pascal VOC数据来说,2010前后有两种计算方式,现在主要是第二种,计算方法如下(Pascal VOC给出的评价文本结果是img_name+置信度+x1_lefttop+y1_lefttop+x2_rightbottom+y2_rightbottom,通过坐标计算IoU,大于0.5的认为是TP,小于等于0.5或者检测到同一个GT的多余框认为是FP,没有检测到GT认为是FN):
假设样本中有M个正样本,且每个样本都有预测的类别置信度和预测的GT(IoU大于0.5),根据置信度顺序给出各处的P-R值,画出曲线,根据样本设定[0/M, 1/M, 2/M, 3/M, …, M/M]这几个recall点,找出每个点之后最大的precision值(如果曲线不能全部遍历完则只遍历到最后出现的recall值,没有的对应点,precision做0处理),以precision为高,相邻recall点之间的距离为宽,相乘相加近似得到曲线与X轴的面积,即为AP
算出所有类的AP,再做平均就得到了mAP。
举个例子:
我现在用训练好的Faster R-CNN测试自己的数据集,总共有三类:drone,bird,kite,最后会在results文件夹下生成三类检测的.txt文件。
比如在comp4_det_test_bird.txt里面,前面几行是:
njust_drone2videotest_0119 0.002 536.2 359.2 564.2 378.1 |
之后需要对上述文本就行处理,主要是筛选检测框,比如设置置信度阈值,使用NMS等,然后根据推测的坐标和真值坐标计算IOU,大于0.5的设置框的GT为1,否则为0。值得注意的是,即使做过筛选后,最后得到的检测框还是可能误检(FP),多检(FP,一个物体框了多个),漏检(FN),大致流程如下:
首先对所有的结果按置信度排序,从高到低,然后根据坐标判断检测是否成功。排好序的坐标每一组都得和真实标注的GT进行比较计算IoU,大于0.5的认为检测成功,那么赋给他的标签就是1(TP),否则是0(FP),同时,每当一个GT被成功检测了,那么就会被标记,后续如果发现有其他的检测与这个GT重复,那么就把IoU最大的当作TP,其他多检的当作FP,遍历完成之后,如果存在没有匹配到的标注GT,也就是漏检,认定为FN。这样一整个流程下来就会得到TP,FP和FN。
借用上头知乎链接的答案,具体讲下怎么计算AP:
在筛选,NMS,比较等步骤之后,假设对于bird这一类,有如下检测结果(IoU>0.5时GT=1,按照置信度排好了顺序):
BB | confidence | GT |
其中BB代表bounding box,其中两个BB1代表一个物体被框了两次,则应属于FP,因此在计算的时候要注意,虽然给出的GT是1,此外还有两个bird没有被检测出来,那么属于FN,整体上实际是正样本的有5+2=7个。现在从上到下以此按置信度大小计算(recall,precison)点对。($recall \in [0/7, 1/7, 2/7, 3/7, 4/7, 5/7, 6/7, 7/7]) $
1.首行以下认为预测值全为0,则TP=1(BB1),BB2,BB5,BB8,BB9实际是1,但是预测为0,所以FN=4+2=6(两个漏检的),FP=0,所以recall=1/(1+6)=0.14,precision=1/(1+0)=1.00;
2.第二行一下认为预测值全为0,则TP=2(BB1,BB2),BB5,BB8,BB9实际是1,但是预测0,所以FN=3+2=5,FP=0,所以recall=2/(2+5)=0.29,precision=2/(2+0)=1.00;
3.第三行一下认为预测值全为0,则TP=2(BB1,BB2,BB1为多余的,算FP),BB5,BB8,BB9实际是1,但是预测是0,所以FN=3+2=5,FP=1,所以recall=2/(2+5)=0.29,precision=2/(2+1)=0.67;
4.第四行以下认为预测值全为0,则TP=2(BB1,BB2),BB5,BB8,BB9实际是1,但是预测是0,所以FN=3+2=5,BB3实际为0,预测为1,BB1多检一个,所以FP=2,则recall=2/(2+5)=0.29,precision=2/(2+2)=0.50;
5.第五行以下认为预测值全为0,则TP=2,FN=5,FP=3,所以recall=2/(2+5)=0.29,precision=2/(2+3)=0.40;
6.第六行以下认为预测值全为0,则TP=3,FN=4,FP=3,所以recall=3/(3+4)=0.43,precision=3/(3+3)=0.50;
7.第七行以下认为预测值全为0,则TP=3,FN=4,FP=4,所以recall=3/(3+4)=0.43,precision=3/(3+4)=0.43;
8.第八行以下认为预测值全为0,则TP=3,FN=4,FP=5,所以recall=3/(3+4)=0.43,precision=3/(3+5)=0.38;
9.第九行以下认为预测值全为0,则TP=4,FN=3,FP=5,所以recall=4/(4+3)=0.57,precision=4/(4+5)=0.44;
10.第十行以下认为预测值全为0,则TP=5,FN=2,FP=5,所以recall=5/(5+2)=0.71,precision=5/(5+5)=0.50
接着根据每个不同的recall值去找对应的最大的precision值,即:
recall>=0.00,precision_max=1.00 |
则
实际上,这就是在P-R曲线上找出一些特定的recall点,然后利用多个矩形的面积和来近似代替曲线与X轴围成的面积。
如果是VOC2010之前,recall值的选取是固定的,即,对应的最大precision为1,1,1,0.5,0.5,0.5,0.5,0.5,0,0,0,此时AP的计算公式是11个precision的和的平均值,为0.5。
在COCO数据集中,IoU要求在[0,5, 0.95]区间每隔0.05取一次作为正样本判断阈值,然后计算出10个类似Pascal VOC的mAP,然后再做平均,作为最后的AP。COCO并不将AP和mAP做区分,COCO中的AP@0.5等同于Pascal中的mAP。
AP是衡量检测器性能的一个综合指标,但是对于你的数据集,可能并不是最适合的,因为有的数据场景认为误检几个影响不大,主要是都能检测出来,那么这时候recall值就大点好;有的数据场景呢,认为漏检几个没问题,但是不能检测错了,那么precision大点好。而AP是对recall和precision做了一个整体的评估,是检测器对数据普遍场景下的检测性能的打分。后续的一些研究工作发现了此评价指标在一些场景下水土不服,以及没有考虑具体物体检测的置信度得分情况而导致泛化能力失衡的情况,并对此做了一些改进,有兴趣的可以阅读下南京旷视研究院的两篇博文做个大概的了解。(blog1, blog2)
Content
**Region proposals–Selective Search(paper, blog,code).**最开始的阶段,算法要通过该方法提取出每张图像上存在物体的可能区域,即建议框,每张图片大概会提取2k左右。Selective Search算法属于经典计算机视觉范畴,主要是利用不同的尺度(颜色,纹理,大小等),采用图像分割,层次算法等,先分割成小区域,然后通过颜色直方图相近(颜色相似),梯度直方图相近(纹理相似)等规则合并,得到最终的proposals,由于这个方法严重限制了整体框架的速度,而且后面也被Faster R-CNN中的RPN取代,因此我也没有兴趣深究,感兴趣的读者可以通过原论文和代码进一步了解。
**CNN feature extraction.**利用selective search得到的预选框由于大小不一,不方便过卷积层后reshape成统一维度的矩阵,因此需要进行resize等预处理。变形操作方面主要就是拉伸和填充的组合。
如下图所示,(A)是原图,(B),©是各向同性变形,(D)是各项异性变形。(B)考虑了proposal周围的纹理内容(context),利用其扩充到,如果遇到了图像边界就利用proposal的像素均值填充;©不考虑proposal周围的像素信息,直接用其像素均值填充到;(D)是直接对proposal resize到,不过在此之前先进行padding处理,padding的尺寸分别为0和16,像素值为proposal的像素均值。论文给出的结论是padding=16加各向异性缩放的效果最好。

网络层面,R-CNN选用了Alexnet和VGG这两个网络,由于VGG采用了更小的卷积核和小的stride,因此最后的检测mAP也更高。在训练方面,R-CNN利用的是在ILSVC数据集上的预训练分类模型,等于是进行了较好的初始化,有了一个比较通用的特征提取器,然后在Pascal VOC这样的小数据集上进行fine-tuning,这样的迁移学习也算当时的一个contribution,但是现在来看已经属于比较正常的操作了。以Alexnet为例,proposal经过其中的5个卷积层之后,得到的是的特征图矩阵,再经过fc6和fc7之后得到了4096个神经元,最后再经过一个有21个神经元的fc,即分类数,最终得到了适合该数据样本的分类器(和GT的IOU大于0.5的那些proposals都会标为正样本,否则为负样本),但是并不能准确预测位置。
**SVM classification.**一般来说,根据图像分类的操作,都是将最后的全连接层改成需要分类个数的神经元,因此针对Pascal VOC来说,可以将最后的fc进行softmax,但是R-CNN却在fc7后面加了个SVM分类器,是什么原因导致这样做精度更高呢?根据论文的说法,Ross在微调CNN的时候,和GT的IOU大于0.5的那些proposals都会标为正样本,否则为负样本,这样的话对bndbox的限制非常宽松,也就是说监督信息不是严格有效的,因为CNN对小样本容易过拟合,因此这样的操作只是为了微调网络,尤其是最后的fc6和fc7,使其能够得到针对Pascal VOC数据的分类特征。采用SVM是因为SVM适用于少样本训练,而且由于是最后的分类,所以IOU的阈值设定也比较严格,目的是为了提供尽量正确的监督信息(GT为正样本,IOU小于0.3的负样本,这个0.3也是调参试出来的)。SVM分类器(可以与sigmoid函数结合,进行概率输出,在scikit-learn package中的SVM函数可以直接输出概率,理解SVM)其实就是的权值矩阵,最后得到了每类的置信值,这样就得到了类别结果。此外还需注意的是,由于GT只有一个,而IOU小于0.3的proposal可能会有很多,这样就导致了训练SVM分类器的时候正负样本不均衡,论文中也提到,SVM的负样本是经过hard negative mining筛选的(负样本的处理是object detection中的一个技术细节和难点),具体怎么做的,我没有继续深究,我准备在Ross的下一篇文章“OHEM”进行梳理。
**NMS非极大值抑制。**SVM分类器输出的是2k个proposal的类别置信矩阵,后面需要对每一类做NMS处理,去除掉无用的proposals,留下最接近的proposals(一个物体可能被selective search提取出了很多类似的proposals)。具体步骤如下:
假设是2000个proposals,然后是21类(加一个background),那么一张图片最后过SVM得到了一个的矩阵,每一列代表这2k个proposals的每个类别的置信度,那么:
1.对此矩阵按列按从大到小的顺序排列;
2.对每列,先选取该列最大的那么proposal,然后与该列后面每个得分对应的proposals计算IoU,如果大于设定阈值,则剔除该proposal,否则认定是这张图片存在该类别的多个物体;
3.对这一列剩下的次大的proposal进行2的操作,并不断重复,直到该列遍历完;
4.对21列(所有类)进行步骤2,3的操作
经过NMS之后,就可以得到位置比较准确且类别置信度较高的一些proposals。
**Bounding box regression.**分类完成并且NMS之后需要对proposals的位置进行精修,因为selective search得到的proposal并不是精确的目标检测器,因此还需要对物体的位置做进一步的修正。
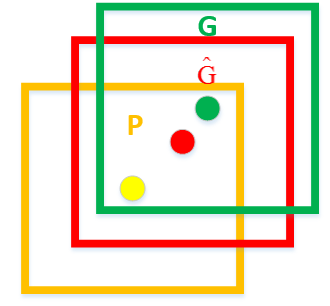
a).如何设计回归?首先是挑选与GT比较接近的proposal(框)进行回归,如果差的太远,是没办法进行学习的。其次也不是直接回归矩形框的四个坐标,而是学习一种框的变换,即从检测框到GT的平移和缩放,这样的话会使网络学习比较稳定,直接回归无规律的坐标可能导致网络不稳定。如下图所示,P代表送入网络的region proposal,G是标注的GT,是学习过后的regression模型预测出的更接近GT的bounding box。其中,下标代表矩形框中心坐标,代表矩形框的宽和高。为待学习的平移变换,为待学习的缩放变换,即:
(这里缩放变换用了exp可能还是因为网络回归小的值容易些,变化大的值不稳定)P实际上代表着proposal的信息,因为是对proposal进行修正,因此在回归学习时候,都可以看作是Alexnet最后一个pool层的线性函数,目的是学习对最后的feature map使其可以变换到真值附近的变换组合,即:
就是要间接梯度下降学习的参数,代表最后pool层出来的结果,是正则项系数,防止过拟合,在论文中Ross提到这个参数很关键,否则效果不好,论文中设的值是1000。是要去学习的准确的变换,即从P到G的变换:
b).怎么训练?为了回归器有效训练,每类样本只采取与GT之间IoU最大的且大于0.6的region proposal,输入的是P和G的坐标信息,以及Alexnet的层特征,然后根据loss函数对每一类单独训练回归器。
Discussion
1.虽然整体繁琐,占用内存大,速度也慢,但是技术框架和细节为后面的改进工作奠定了整体基础,具有开创意义;
2.论文写得非常详实,没有难懂的地方和句子,通读以后对其工作和贡献了解得很清楚;
3.考虑问题很全面,实验的各个因素都考虑到了,而且做了很多对比试验(Ablation Study),让人信服,有理有据。Ross的写作技巧和框架对自己写论文有很大的借鉴意义。
4.Ross论文中的推荐的object detection errors analysis ,进一步了解目标检测的错误分析。
SPPNet
Introduction
何恺明在ICCV2015上作的tutorial,Convolutional Feature Maps --Elements of efficient (and accurate) CNN-based object detection,讲解了SPPNet的一些内容,同时对比了R-CNN, Fast R-CNN和Faster R-CNN。
SPPNet是在R-CNN的基础上进一步提高目标检测的速度和精度。何恺明等作者认为,R-CNN每次都要将Selective Search提取出的2k左右的region proposals进行crop和warp,然后分别过卷积这样的操作太费时间而且可能做了很多重复的计算,因此他们认为可不可以直接将full image过一次卷积网络,然后在feature map进行操作,毕竟图像的特征在卷积提取之后都是一样的,由此SPPNet应运而生。
SPPNet的好处是速度得到了大幅提升,而且简化了部分操作,但是随之而来的问题是:
region proposal的大小不一,但是conv之后的fc层是固定的向量长度,怎么去适应?
解决这个固定尺度的问题后,那么怎么找region proposal对应的feature map区域?
对于第一个问题,SPPNet提出了spatial pyramid pooling(SPP, 空间金字塔池化),通过多次pooling输出不同尺度(预设好尺寸)的特征图并进行concatenate叠操作(类似U-Net),得到了固定长度的特征向量,这也是该论文的主要contribution;对于第二个问题,SPPNet通过简化receptive field和对应中心坐标计算,来近似得到region proposal图像的top-left, right-bottom坐标对应在最后feature map上的坐标,从而确定区域。

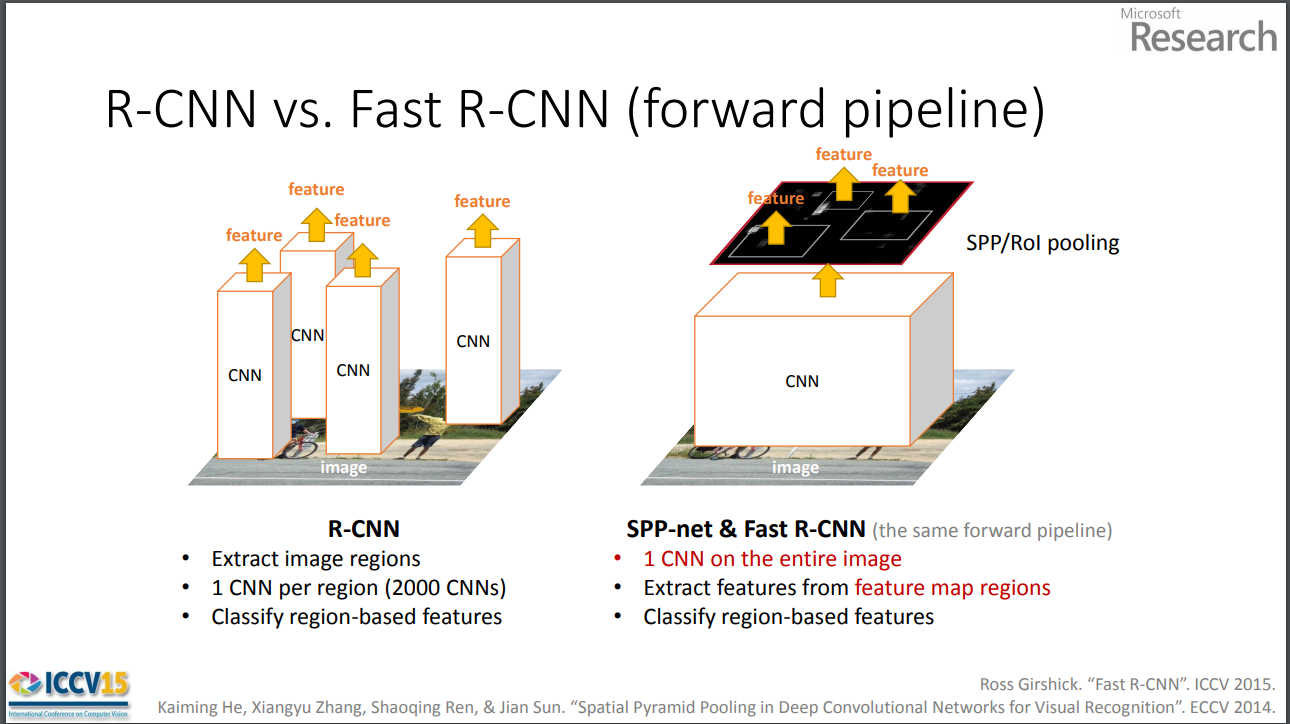
Content
SPP空间金字塔池化
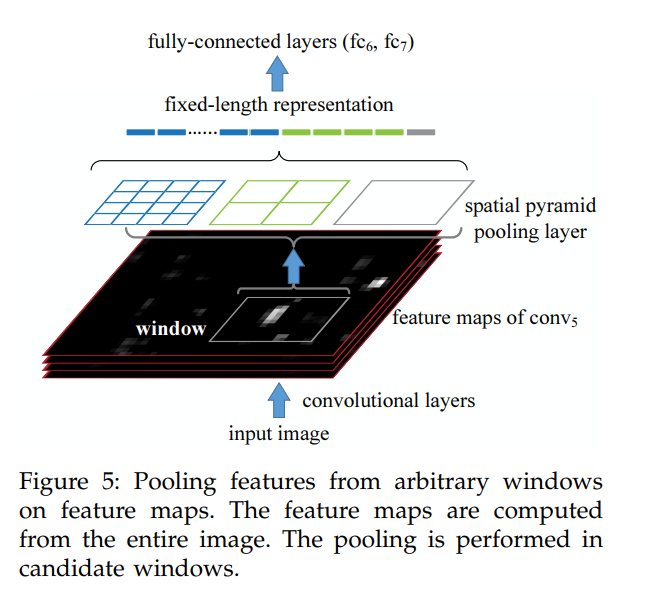
不同的regional proposal对应的feature map区域尺寸看成一个个不同尺寸的小feature map,然后在该map上做几次不同的maxpooling,得到尺度依次变小的特征图,不改变channel数,然后将这些不同尺度的金字塔特征图reshape成一维的向量,然后合并在一起形成固定维度的fc层。由于特征金字塔的尺度是预设的,所以不管region proposal或者image的尺寸如何,都不会影响最后的分类。
此外,由于可以tolerate multi-scale,论文也采用了多尺度的图像去训练,并做了实验,结果也证明确实比单一尺度要好。
We develop a simple multi-size training method. For a single network to accept variable input sizes, we approximate it by multiple networks that share all parameters, while each of these networks is trained using a fixed input size. In each epoch we train the network with a given input size, and switch to another input size for the next epoch. Experiments show that this multi-size training converges just as the traditional single-size training, and leads to better testing accuracy.
Note that the above single/multi-size solutions are for training only. At the testing stage, it is straightforward to apply SPP-net on images of any sizes
SPP is better than no-spp, and full-image representation is better than crop
region proposal 映射
在进行SPP之前,网络需要知道最后卷出来的feature map中哪些部分和最初Selective Search得到的原始region proposal是对应的。论文对此方法的解释比较简略,只在附录最后做了提及,估计也是个工程性,实验性的处理。其大致思路前面也已经说过,就是找左上和右下的对应点,而这种对应的映射关系主要由网络的感受野(receptive field)决定。

感受野
The receptive field is defined as the region in the input space that a particular CNN’s feature is looking at (i.e. be affected by)
简而言之,感受野就是当前你的特征图上的像素点对应的是前面特征图的哪些部分区域(这个点是从多少视野中抽象出来的),这个区域一般是矩形大小的。对应分类来说,一般网络越深、感受野越大越好(高层语义信息越准确),对于目标检测,如果感受野太大,那么小目标的信息可能丢失,因此需要针对具体的任务去分析调节。
对于卷积之后特征图大小计算,感受野概念和推导来源,可以参考下面的references,我在之后的内容中就直接给出公式和结论了。
假设特征图是正方形的,特征图尺寸是,感受野尺寸是,卷积核kernel_size是,步长stride是,填充padding大小是,感受野中心坐标为,下标代表从上到下的顺序标号,则:
经过一次卷积后特征图大小变为(向下取整,比如22.5取22):
当前特征图的像素点对应上一特征图的感受野尺寸是(根据上面的公式逆推,下标意义不完全准确):
当前特征图在上一个特征图的感受野大小就是卷积核大小,即。感受野计算一般不加padding,因为感受野是指在原图上的感受野,与填充无关,虽然逆推公式时候padding会有影响,但是将其忽略然后近似计算。如果要计算最后特征图在原图上的感受野,依次递归即可。
举个例子: |
特征图像素点对应上一个特征图的感受野中心坐标:
这时候要考虑padding,因为坐标有影响。尺寸加上坐标就可以定位region proposal在特征图与特征图之间的映射关系。
NIPS 2016的论文Understanding the Effective Receptive Field in Deep Convolutional Neural Networks提出了有效感受野的概念,也就是说感受野内部的每个像素的作用和贡献不是相同的,有效感受野仅占理论感受野的一部分,一般中心较多,属高斯分布影响。

上图是何恺明简化的计算中心点的公式,也就是计算region proposal左上和右下坐标点的方法。
设,当为奇数时,,则;当为偶数时,,则,由于坐标取的都是整数,所以近似认为,也就是说感受野的中心坐标只跟步长以及后面的中心坐标有关,因此通过这种关系一步一步将原图的region proposal坐标映射到feature map上。另外,可能考虑到近似处理的原因,论文最后对映射到feature map上的坐标值做了进一步处理:
左上坐标值:;
右下坐标值:;
也就是说,把区域缩小一点(左上点下移,右下点上移),应该是何恺明考虑到最后feature map上的点计算感受野映射回去的时候扩大了区域,所以做了一个这么经验化的处理。
最后总结一下SPP方法,通过原图region proposal的左上和右下坐标,分别以各自作为中心坐标扩展出感受野大小的区域,然后映射到feature map上,找到对应的像素点,这样就定位出了原图region proposal对应的特征,然后对该特征进行预设金字塔尺寸的池化,最后对不同的特征图reshape,“叠”在一起给fc层,进行分类。
Fast R-CNN
Introduction
内容有参考:
Ross Girshick在ICCV 2015上对自己论文的讲解,在他的个人主页可以找到slide
Fast R-CNN吸收了SPPNet的优点,并针对R-CNN冗余的的多推理结构,以及带来的占用内存资源多,推理速度慢的问题进行了改进,采用shared computation和mutli-task learning将整个流程(原始图像region proposal提取除外)合在了一个网络中,最终使得推理速度得到了显著提升,占用内存减小,训练也更加容易便捷。
R-CNN的问题
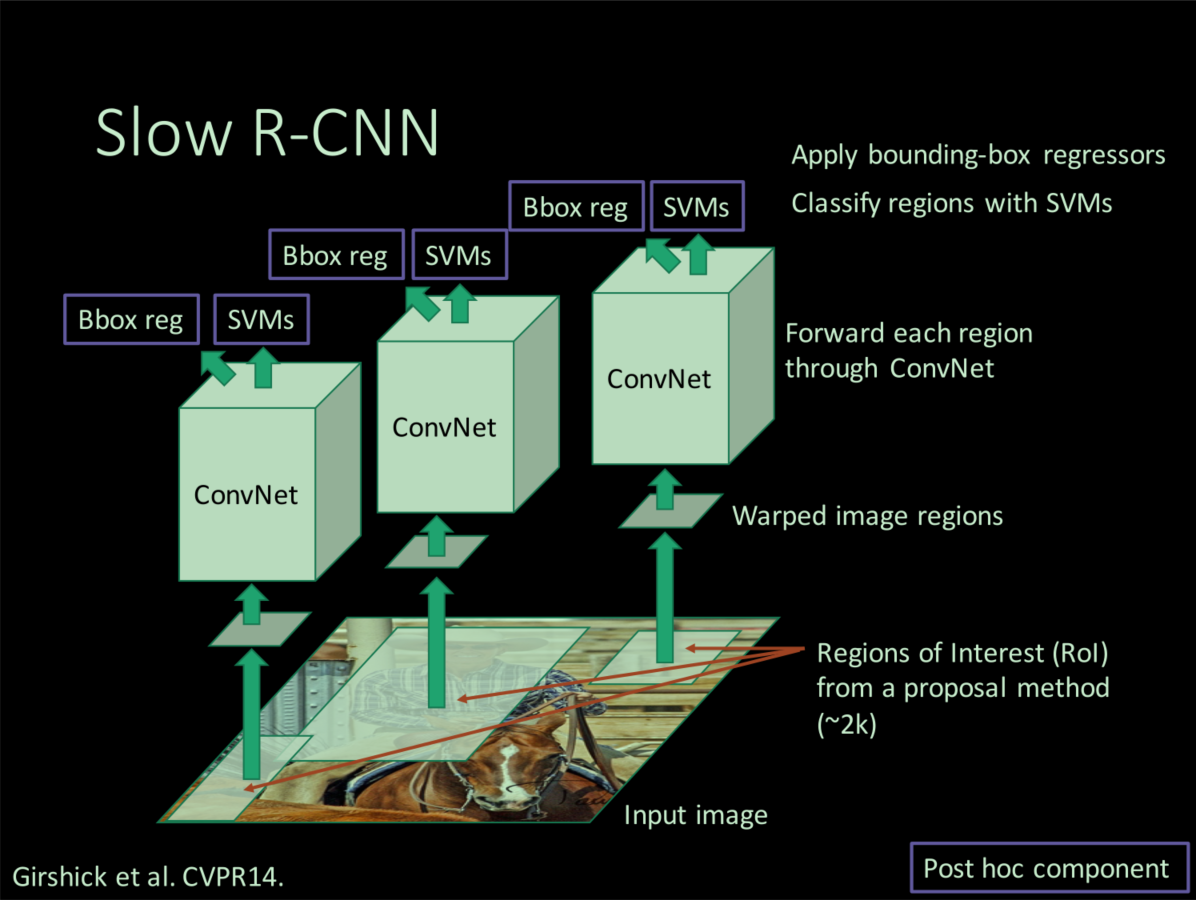
- 分阶段训练,多个步骤,首先是softmax分类网络,然后时linear SVM分类器,最后是bounding-box regression,而且每个阶段的训练样本都得按照各自的规则重新选取;
- 训练时间很长(84h),region proposals 要一个个地进行resize,然后一个个送进网络,占用大量硬盘空间;
- 训练好的结构推理时间长(利用vgg16 backbone一张图片47s);
SPPNet的问题
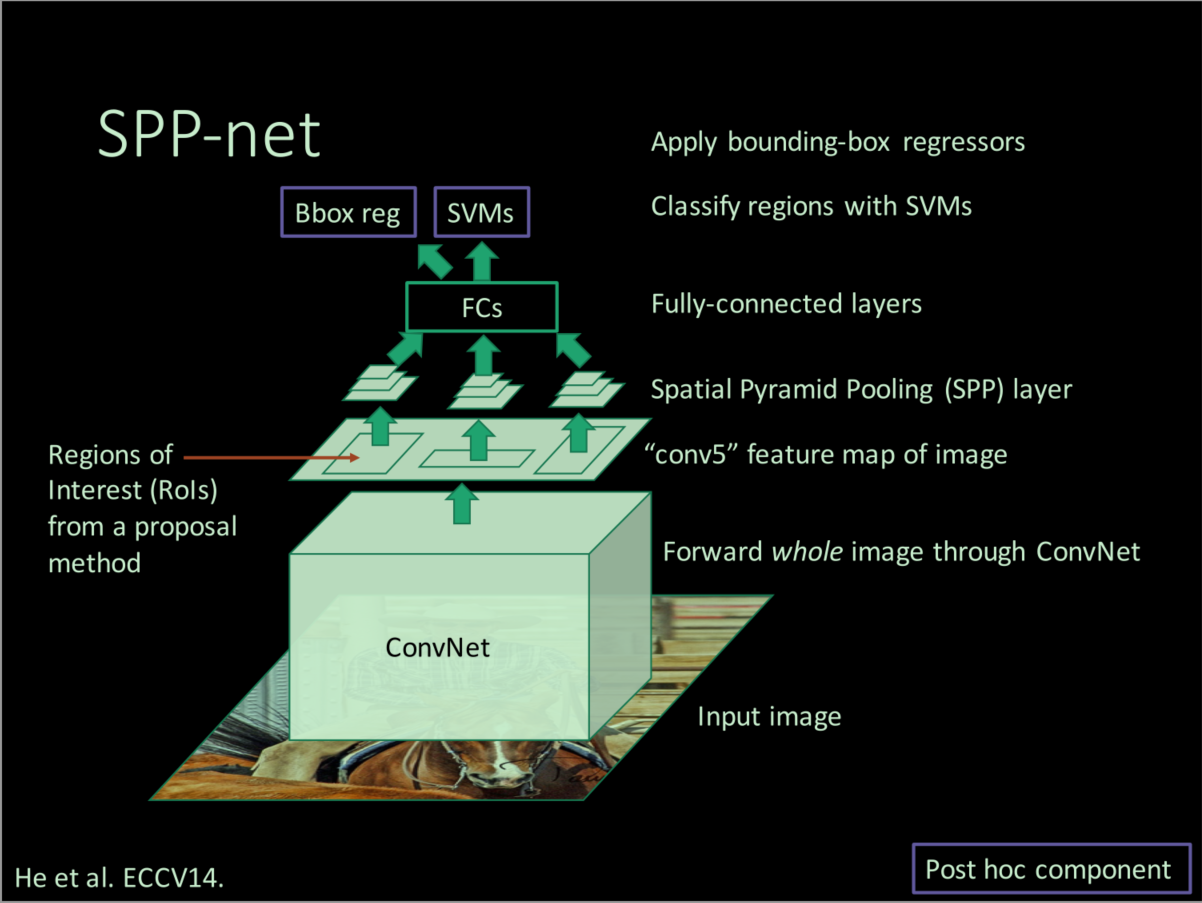
SPP进行了图像级别的计算共享,只需在最后的feature map上进行region-wise computation计算,加速了推理时间。但是由于SPPNet的其他部分完全照搬R-CNN,所以也存在训练繁琐,训练时间长,占用磁盘空间大的问题。此外,Ross认为,SPPNet引入了一个新的问题:在训练时,SPP layer以下的卷积层等layer的参数无法更新。
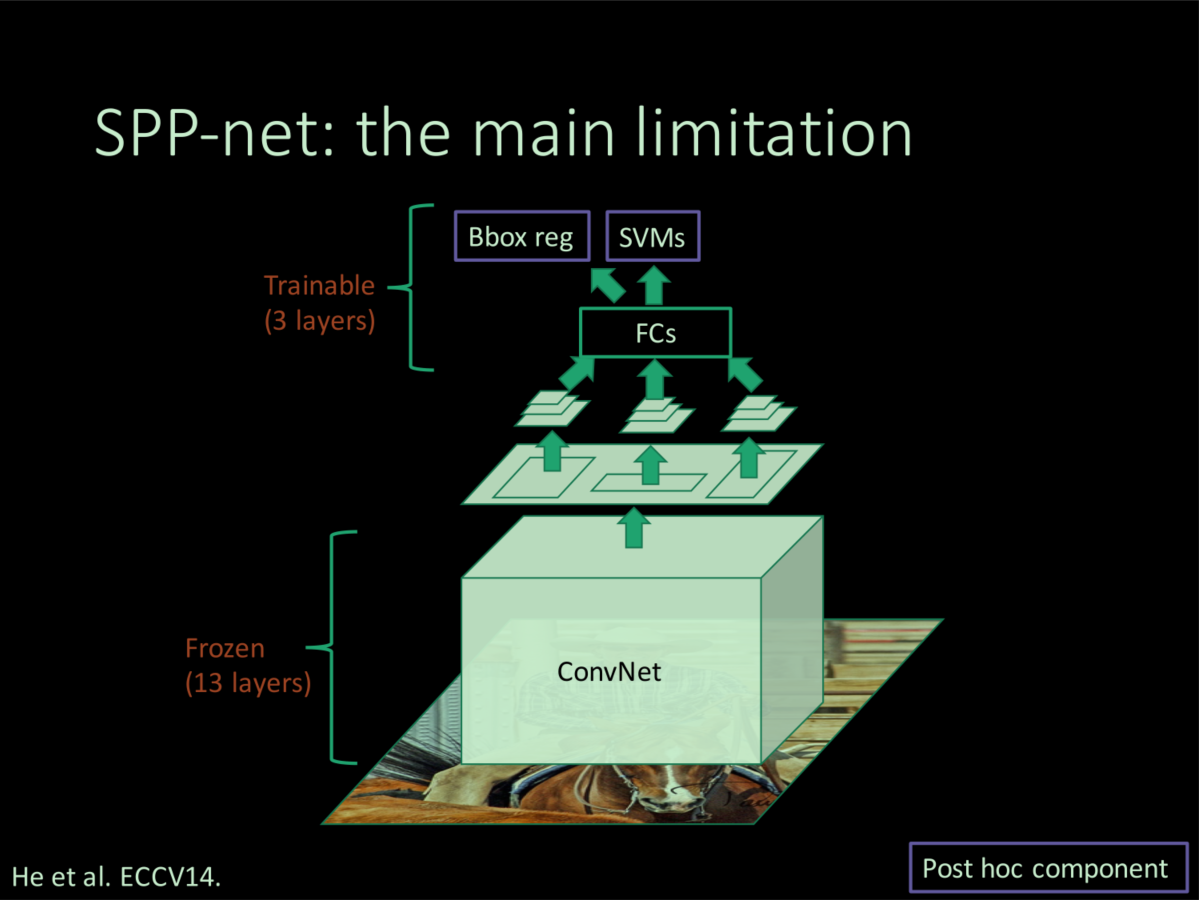
其原因主要跟mini-batch sample样本的策略有关,Ross也在其ICCV 2015的oral中解释了。SPPNet在训练时,一个batch随机采样128个regional proposal,这样的话样本有很大概率是来自于不同的图片,特征图上的一个proposal对应到原图上的感受野通常很大,最坏的情况是感受野是整个图像,那么每个batch可能就要去计算很多个几乎是整幅图像的梯度,而且不同图像间不能共享卷积计算和内容,反向传播会很慢且很耗内存。
Fast R-CNN的优缺点
单个网络训练,占用内存少;
推理速度快,精度更高;
region proposal依然耗时;
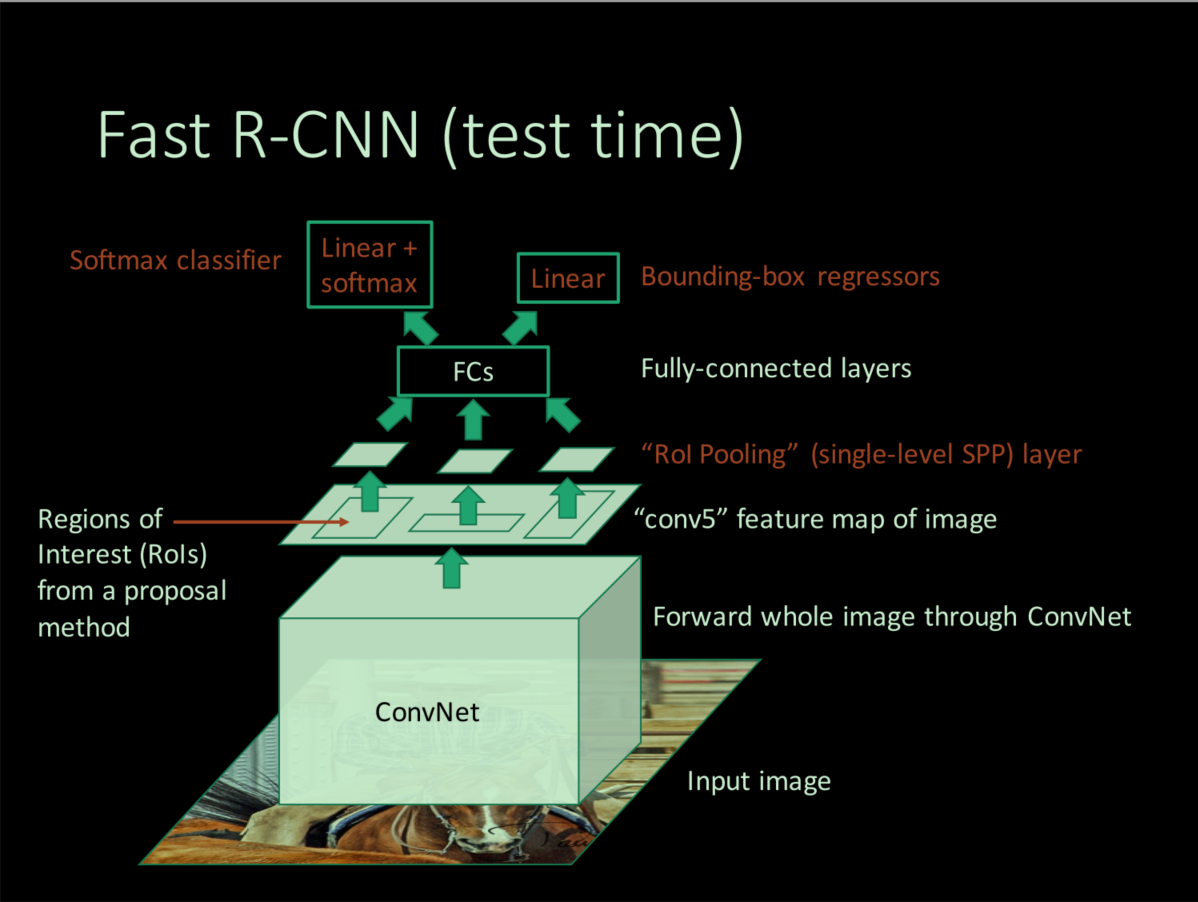
Content
如上图,Fast R-CNN的推理流程如下:
输入任意size的图片和Selective Search产生的region proposals;原图经过一系列卷积层得到最终的特征图,并根据原region proposal找到feature map上的对应特征区域;对特征区域进行RoI pooling,得到固定大小的特征图,并经过fc层得到固定大小的特征向量(可由SVD分解加速推理);特征向量继续向后传递产生两个branch,一个用softmax估计region proposal的类别(N+1个神经元),另一个回归bounding-box的平移和伸缩变换系数(4个神经元);最后利用NMS剔除多余的框。
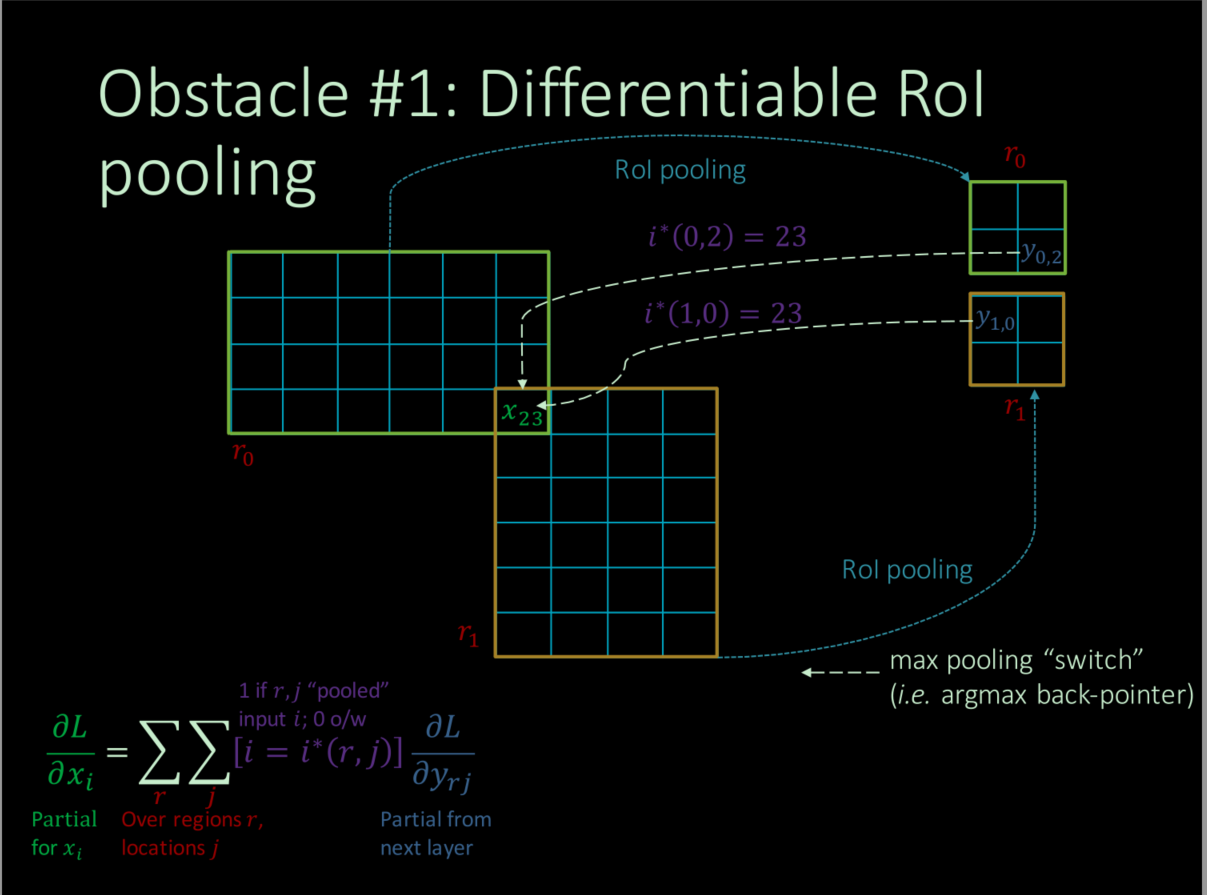
RoI pooling
RoI pooling是特殊的SPP,因为只有一个尺度的pooling,目的是为了不同尺寸的region proposal产生固定size的输出,兼容后面的fc层。论文中提到使用多尺度pooling对精度会有较小的提升,但是会带来成倍的计算量,所以只用单尺度是一种trade-off。此外RoI pooling的网格尺寸是自适应的,利用原proposal大小和期望输出的大小进行计算。
由于RoI pooling采用max pooling,是可微分的,用于BP进行反向传播更新参数。但是由于一幅图像中不同proposal之间内容会有重叠,所以特征图上一个比较大的值可能出现在不同的pooling后的proposal上,因此论文提出直接将其相加。

one-stage training–SGD & multi-task loss
如前所述,如果采取SPPNet mini-batch sample样本的方式,梯度计算会很慢,将会很难训练网络。Fast R-CNN采用了向同幅图片随机采多个region proposals(hierarchical sampling)来加快梯度计算和传递:先随机采两幅图片,然后从这两幅图像中分别再各自采取64(128/2)个proposals,这样的话感受野会有很大重叠,梯度计算就不会很慢,占用内存也不会太大。但是Ross认为这种方式可能会导致网络收敛很慢,因为proposals很多都是相关的,不过实际中并没有出现这个问题。
分类损失函数:,依然是交叉熵,分类采用softmax,未继续采用svm,实验证明采用前者精度更高,原因可能是因为多任务学习以及RoI pooling的作用。
回归损失函数不再是平方损失函数,而换成了损失函数:
回归分支输出预测的平移伸缩变换参数:,根据预测结果得到一个预测框,计算出真实平移伸缩参数:,然后计算误差不断逼近即可。
训练中分类正样本是与GT的IoU属于[0.5,1]之间的proposal,负样本是与所有类别GT的IoU的最大值落在[0.1, 0.5)之间的proposal(0.1来自困难样本挖掘,论文中一笔带过),两者按照1:3配比(没有这个约束来平衡正负样本,训练出的模型精度会下降)。
Ross也在论文中做了对比实验,验证多任务学习确实多两者都有提升,也进一步说明这种一个流程下来的结构是符合期望也有不错的效果。
此外Ross也研究了多尺度训练和单尺度训练的问题(曾作为SPPNet的一个小contribution),也就是输入的原始图像的size不同,实验证明,deep neural network善于学习尺度不变性,对目标的scale不敏感,虽然多尺度效果效果确实好一点点,但是没必要以时间和硬件资源的牺牲来换取。
SVD分解或许对提高目标检测的实时性有潜在的帮助
由于开始提取出的region proposal比较多,所以大部分时间都会消耗在全连接层上(一张图片只要过一整遍卷积),为了提高速度,Ross实验了SVD分解全连接层,结果证明时间可以得到不小的提升,同时只损失很小的精度。
假设全连接层输入为,输出为,权重矩阵为,尺寸为,则:
其计算复杂度为,现对进行SVD分解,并用前个特征值近似代替,则:
实际上上述操作将一个全连接层拆成两个小的全连接,是中间的全连接层。经过SVD分解后的计算复杂度变为,如果比小不少的话,可以显著减少计算量。
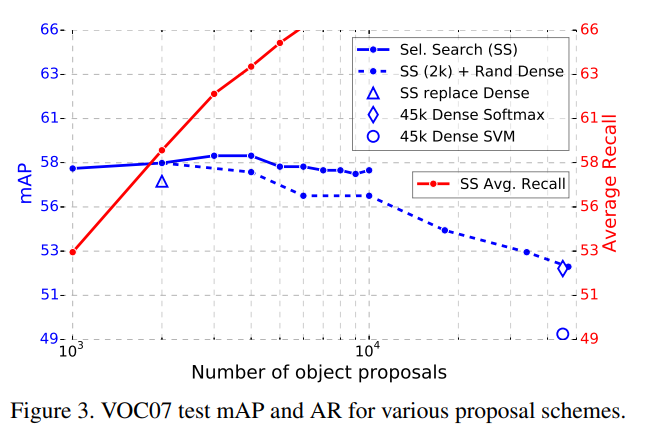
more proposals is harmful
由于region proposal的提取直接影响着后面检测的准确度,为了更高的recall,就要尽可能让region proposal覆盖到所有图像中的object,所以生成越多可能越好,但是Ross在实验中发现并不是这样,逐步增多Selective Search生成的region proposal的数量,发现mAP先增大后减小,我猜想可能是因为太多的proposal导致了相似信息增多,使得网络训练出现过拟合。
Discussion
Ross官方吐槽:一体化proposal提取。

Faster R-NN
Introduction
内容有参考:
Ross Girshick 在ICCV2015tutorial上的演讲Training R-CNNs of Various Velocities: Slow, Fast, and Faster
Faster R-CNN的主要贡献在于提出anchor机制,利用RPN网络和Fast R-CNN一体化检测框架,实现一个完全end-to-end的目标检测网络。因此,阅读该论文需要解决两个主要问题,而且大部分内容应该着重解决第一个问题:
RPN是如何工作的,具体设计流程和实现细节?
PRN加上Fast R-CNN怎么训练?
Content
Faster R-CNN是个非常复杂和精细的结构,包含了很多细节和参数,只通过读论文去完全了解是不现实的,想真正理解必须要去读下源码,如果能手撕出来的话就更好了。
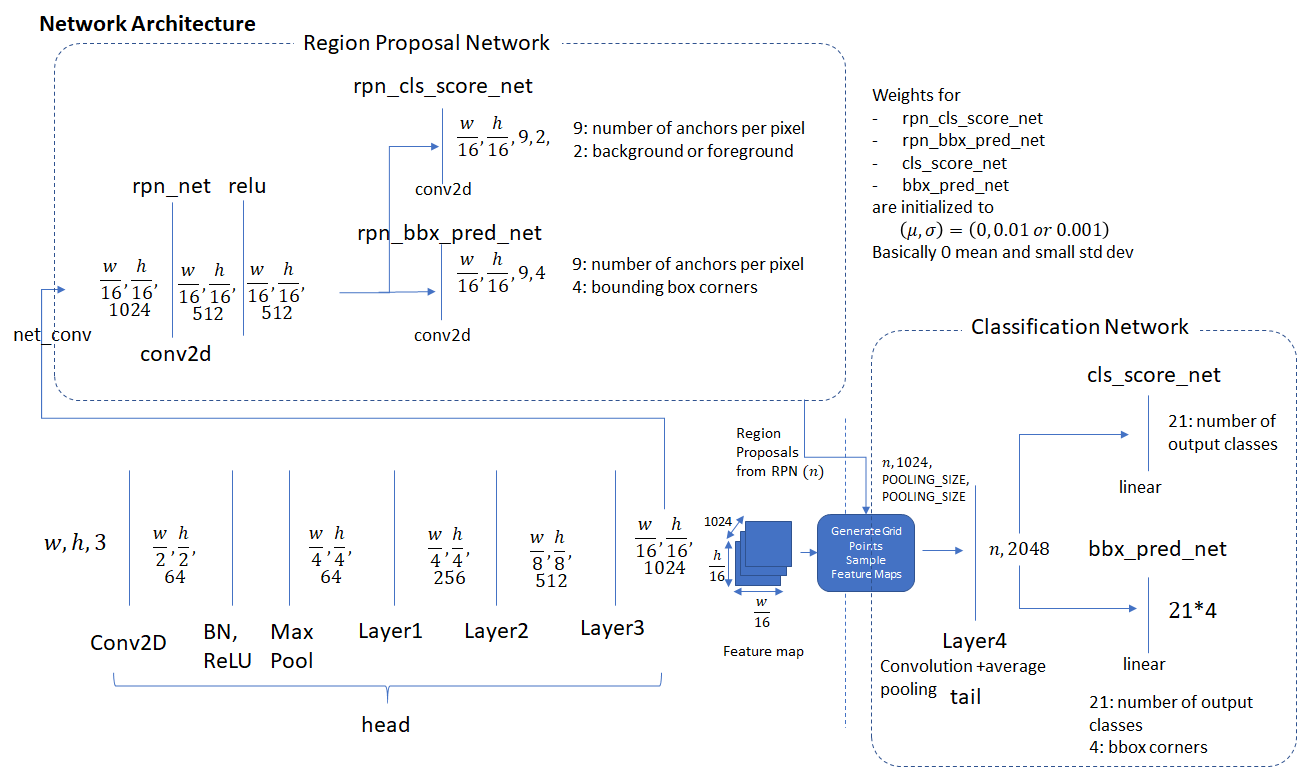
上图是Faster R-CNN的整体网络框架,图片在进入网络前要减去RGB三通道像素均值,并适当resize处理。处理好的图像矩阵送入一系列卷积层进行特征提取,过max pooling缩小特征图尺寸,在特定的卷积层后,特征图送入RPN网络,再过一个的卷积层,然后分别送入两个的卷积层对生成的anchor进行前景/背景的二分类,并对其进行靠近GT的坐标回归修正;之后从中挑出topN的已经修正过坐标的anchor给RoI pooling从最后的特征图(输入PRN的特征图和RoI pooling的特征图是一样的)中抠出相应的feature region然后合成固定长度的向量送给最后的fc层去分类所有的类别,回归所有类别的坐标,进行二次修正。
RPN
RPN的全称是Region Proposal Network,是用以替代R-CNN和Fast R-CNN中的Selective Search方法,实现端对端的object预选框的提取工作。神经网络擅长于分类,同时我们结合R-CNN等前人的工作,要想通过网络去提取出一系列预选框该怎么做?以往经典视觉是通过滑动窗口或者图像金字塔的方法,但是类似的方法移植到网络上太费时间:可以用不同的卷积核代表滑动窗口,然后卷完再分类;用不同尺寸的特征图代表图像金字塔,然后再分类,这样的话就等于几乎复制了一遍R-CNN这样的架构,速度可能会更慢。因此,任少卿采取了pyramids-of-filter,pyramids-of-images之外的另一种替代的方法:pyramids-of-reference-boxes,也就是说,在RPN里面,我们自己预先根据一定的规则,生成许多的矩形框,覆盖住整个图像的几乎每个object的内容,然后再用网络去识别哪些是“好的”,哪些是“坏的”,然后让“好的”尽量好点,送给Fast R-CNN去进一步识别检测,“坏的”直接丢弃掉。
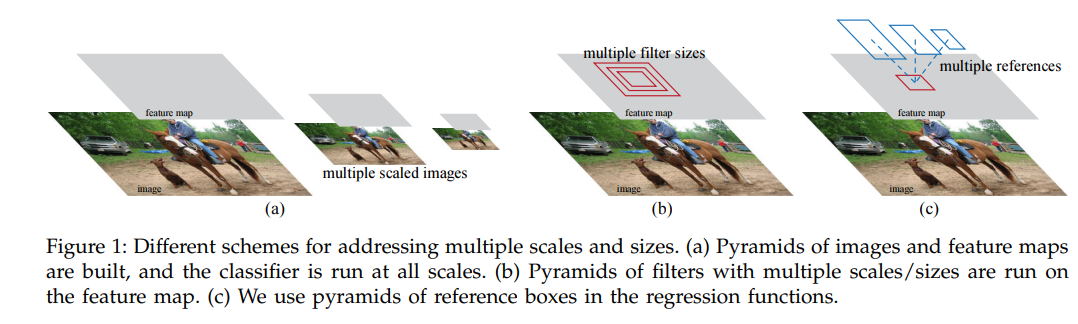
这些参考框称为anchor,具体生成方式如下:
参照Faster R-CNN的网络结构图,假设输入给RPN的特征图尺寸比原图缩小了16倍,特征图上的每一个像素点,或者说grid,可以看作是原图的的gird的缩小版,然后以每个原图上的这些的grid的中心为参考点,画出预设面积和宽高比的矩形框,这就作为一个初始的预选框。论文设置了三个anchor scale(代表面积)和三个宽高比,分别是[8, 16, 32],[0.5, 1, 2],其中anchor scale的base是16,也就是说预设的面积分别是:,宽高为:(这里说个题外话,在训练自己的数据集的时候,可能需要修改anchor scale和anchor aspect ratio,但是我自己平时实验发现,改anchor scale的作用稍微大点,比如检测小的目标的时候,改ratio效果就不怎么明显,我曾经统计了标注数据的长宽比例,然后根据此比例当作anchor aspect ratio训练,结果效果差不多,我猜想这可能就是二次回归修正的功劳,只要你覆盖到了,挑选到了就好说。)
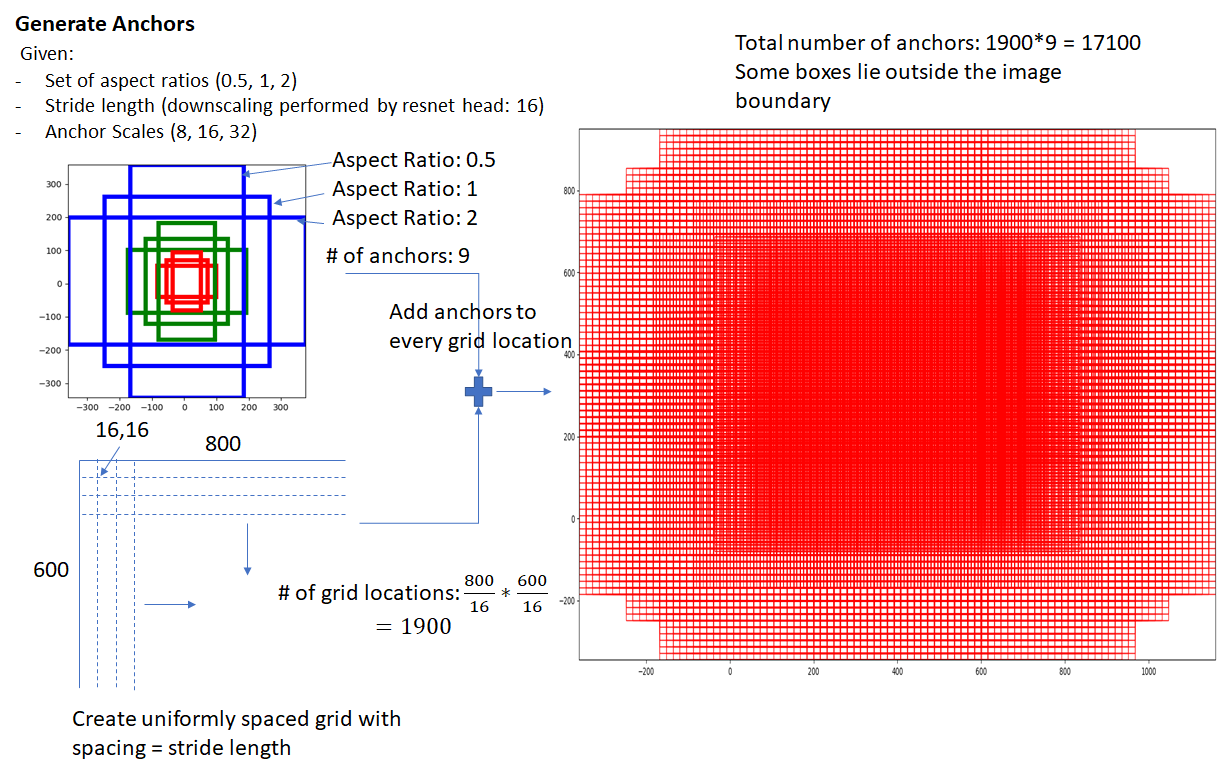
在第一次读论文的时候我以为是根据送进RPN的那个特征图的每个grid的感受野去得到原图的位置,然后画框,但是这样的话,每个grid在原图的位置就固定了,而每个grid代表的感受野不能像anchor那样去覆盖几乎所有的object,数量远不如anchor那么多,那么必然是会漏掉的。另外一点是跟PRN的网络结构有关。
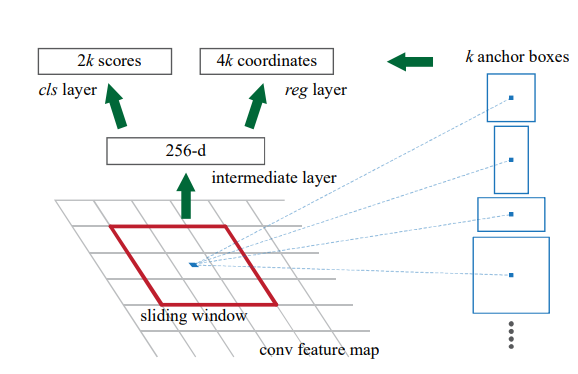
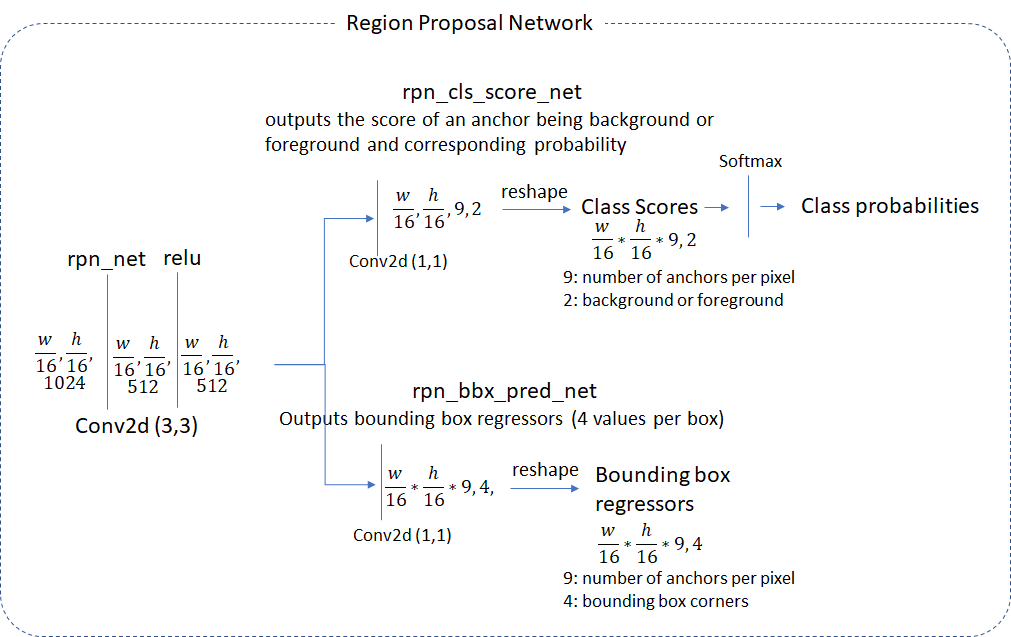
看上面两个图,RPN不是用fc来分类和回归的,而是直接用全卷积来完成,有点类似FCN。一开始是对输入的特征图进行卷积,完成进一步特征提取,非线性化和降维之类的工作,然后再用两个卷积完成分类和回归,值得注意的是,里面的卷积操作不改变feature map的尺寸,也就是grid的数量不变,最后分类和回归卷积层输出的tensor的尺寸分别是,通道数分别为18(前景\背景2类,每个grid有9个anchor)和64(每个grid有9个anchor,每个anchor回归4个坐标),其后的reshape是便于softmax和回归处理。
也就是说,RPN通过全卷积,强制让网络去学习每个grid生成的9个预设anchor的质量,并进行适当的修正。实际上,我个人还是比较疑惑的,我不理解为什么这种形式可以去学习特征图在原图对应的anchor哪些是promising的,因为anchor只在训练时分配GT时有用,网络学习时并没有把anchor作为输入的一部分,但是事实证明,RPN确实可以学到,毕竟Faster R-CNN的检测效果摆在那儿。我大概猜测,特征图的每个grid经过卷积后,包含了这9个anchor的一些信息,再分别经过卷积后又分别提取出了类别和坐标信息,网络隐式地学习到了anchor的存在以及他们的信息。
此外,论文中还提到anchor这种方式也具有平移不变性,就是你物体动了,我anchor也会跟着动,这对于图像分类问题来说是很好的一个特性,不管物体在哪个位置都要求较高的准确性。但是对于目标检测来说,还需要定位出物体在图片上的位置,因此平移不变性会抹掉这点。
RPN的训练和推理不是完全一样的。训练RPN时,预先产生的anchor数量很多,可能有上万个,这么多的框确实会包含到几乎所有的object信息,但是很多都是冗余的,也有很多是背景,因此不能全部拿去训练,否则不仅速度慢,效果可能还不好。
论文中训练的anchor总量只有256个(也就是说每次训练只有256个位置有GT,没有GT的就不去计算误差),但是每张图片生成的训练anchor的位置是不一样的,所以图片比较多,训练比较充足的情况下,基本上整个网络应该都是可以训练到的(但是我感觉有些anchor位置可能就是比较容易选中训练,比如原图中心部分)。
训练RPN时候需要先计算anchor的label和坐标变换系数:
foreground认定:anchor box和GT box的IoU超过了设定阈值(论文是0.7),为了防止没有超过的,对于每一个GT box,anchor box跟它有最大IoU的也认为是前景框;
background认定:anchor box和GT box的IoU低于设定阈值(论文是0.3);
落于两个阈值之间的认为是“don’t care”。此外,还有一个
TRAIN.RPN_FG_FRACTION参数,一般是0.5,也就是每个batch size中采取的前景anchor只有个,如果超过了,就随机挑128个。
训练好的RPN需要给Fast R-CNN提供一些可靠的RoI,这时RPN进入推理阶段:
将PRN输出的偏移量给原始的anchor,得到新的区域,同时带有置信度score;
对超出图像范围的框进行裁剪,保证框都在图像内部,这一步没有改变框的数量;
丢掉小于设定的最小尺寸(
TRAIN.RPN_MIN_SIZE = 8)的anchor;根据置信度,选择topK(
TRAIN.RPN_PRE_NMS_TOP_N = 12000)个框,和设定的NMS(TRAIN.RPN_NMS_THRESH = 0.7)阈值,通过非极大抑制去除冗余的框;从NMS之后的框中,选择得分为topN(
TRAIN.RPN_POST_NMS_TOP_N = 2000)的框作为region proposal输入给Faster R-CNN;
到此为止,RPN完成了类似Selective Search的工作。
类似于Fast R-CNN的操作,这些2000个region proposal并不会全部进行RoI pooling,而是从中挑出128个样本进行训练:
region proposal与任一GT box之间的IoU 大于阈值(TRAIN.FG_THRESH=0.5)认为是前景,在0.1(TRAIN.BG_THRESH_LO)和0.5(TRAIN.BG_THRESH_HI)之间认为是负样本;
从前景中挑出一定数量(batch size乘以比例)作为正样本,比例为TRAIN.FG_FRACTION = 0.25,如果正样本没有这么多,则全部选出来,其他的用负样本凑。
如果使用VGG16作为特征提取网络,那么送入RPN的特征图就是最后的特征图,然后利用RoI找到基于原图的128个region proposal对应在这个特征图上的特征向量,最后送到fc层进行分类和回归即可(回归坐标的时候有个bbox_inside_weights,只有前景的时候为1,背景为0,计算loss时候通过这个weight来抹掉背景)。
对于resnet101而言,网络相对而言已经很深了,上面提到的平移不变性此时在最后输出的特征图上基本已经消失了,包含的都是一些高层的语义信息,如果还是把最后的特征图给RPN,那么特征图再去卷积学习anchor的信息,然后提取,将会很难,最后的检测结果也不一定理想,所以此时送入RPN的特征图需要稍微往前些。一般我看的都是把Conv4出来的特征图送给RPN,然后RoI pooling提取出对应的特征区域后再过最后的Conv5,最后送入fc。
此外,RoI pooling也是影响Faster R-CNN精度的一个部分,后面出现了RoI Align(Mask R-CNN), Crop pooling(Spatial Transformer Networks, blog), RoI warp(blog)等取代,目的都是想尽可能地提高回归精度。这些细节我们后续再谈。
在利用Faster R-CNN进行预测的时候,跟训练Fast R-CNN部分差不多,但是region proposal的数量等参数会有所不同,比如PRN在NMS之前的nchor数量设置为6000,在NMS之后设置为300,然后Fast R-CNN直接对这300个进行推理,NMS之后输出预测框即可。
如何训练Faster R-CNN?
RPN网络的loss函数是二分类交叉熵和回归损失:
分别是分类正负样本mini bacth size(256),anchor数量(大约2400)正则化系数和两个loss的权重系数,论文中说明前两个正则化系数可以不用,效果没差,也不是敏感系数,取值扩大100倍也不会太影响精度。
回归部分依然是学习平移和缩放变换系数,按照我前面的说法,RPN是强制是学习有anchor这么个东西,然后再去学习辨别anchor,修正其位置。论文中给出的公式也说明,RPN应当是先学到anchor的位置,再去学GT的位置。当然,给回归部分的GT是anchor和对应GT box之间的变换系数。
Fast R-CNN部分的loss在前一节已经说了,就不再赘述,所以Faster R-CNN一共有rpn_cls, rpn_box, rcnn_cls, rcnn_box这四个loss。
最后需要解决的是Faster R-CNN是如何联合训练的问题。RPN结合Fast R-CNN有点像GAN,但是两者之间不是对抗的关系,而是相互依存的,而且Fast R-CNN更依赖具有良好性能的RPN多一点。作者在论文中分别提到了3种方法,分别是:Alternating training, Approximate joint training, Non-approximate training
Alternating training是分别训练两个网络,比如用CNN特征提取网络VGG16去初始化RPN,训练让其收敛,再让RPN产生的proposal去训练Fast R-CNN,让其收敛…循环往复;Approximate joint training, Non-approximate training都是将其当成一体的,直接利用SGD训练,两种的区别在于前者丢弃RPN的bbox预测梯度,后者则不丢弃,这两点论文都未细说具体细节,比如丢弃RPN的回归梯度的话,anchor还需要向GT box修正吗?
根据其他博客的内容,官方源码给出的训练思路是这样的(类似第一种交替迭代训练方法),估计这也是目前常用的流程(可能要看完源码之后才清楚这件事):
利用在ImageNet上预训练好的CNN模型,训练RPN;
利用上一步训练好的RPN产生的proposals训练已被ImageNet预训练模型初始化的Fast R-CNN:
利用上一步的Fast R-CNN初始化RPN,不更新共享的特征提取网络,仅仅更新RPN独有的卷积层,重新训练RPN;
加入Fast R-CNN,形成一个整体,但是只训练Fast R-CNN特有的卷积层和fc层,共享卷积层参数冻结,proposals来自上一步训练好的RPN;
上述过程类似迭代训练并且进行了两次,作者提到循环多次没有更多的提升。
Discussion
Faster R-CNN中最大的contribution可能就是anchor的使用了,解决了物体中尺度的多样性问题。此外,根据这篇博客的内容,anchor的使用还顺带解决了gt box与gt box之间overlap过大导致gt box丢失问题。大意就是两个不同的物体标的框重合度很大,导致CNN特征图里面也分不清了,这样的话这两个物体可能一起存在特征图的一个grid里面,就会丢掉一个物体,但是anchor是在原图搜的,每个grid都有不同尺度的内容,因此可以一定程度缓解recall降低(漏检)的问题。当然“抠图”来进行二次回归的操作,也一定程度上解决了级联回归的feature alignment问题。
(最近的新文章: IoU-uniform R-CNN: Breaking Through the Limitations of RPN,还没来得及看,后面搞懂了再来开一篇说下,顺便也加上anchor free)
基于pytorch的faster rcnn中的config文件,里面设置了几乎所有的参数:
# Training options |
OHEM(Online Hard Example Mining)
Introduction
论文全称是"Training Region-based Object Detectors with Online Hard Example Mining",code
对样本进行挖掘,自动选出困难样本让网络学习,提高检测精度。
Content
传统机器学习方法,比如SVM,在进行分类训练时,会采取 ”hard negative mining“这样的bootstrapping策略对难以学习的样本进行选取。大致流程是先用正样本和随机采样的负样本组成初始训练数据集,训练一会之后(比如差不多收敛了),去掉容易分类的样本,然后加入一些现有模型不能很好判断的样本,重新进行训练,迭代几轮之后得到最后的分类模型。
Ross等人受到此方法的启发,想在基于region-conv-based这样的object detection方法上也进行困难样本的挖掘。
Our motivation is the same as it has always been – detection datasets contain an overwhelming number of easy examples and a small number of hard examples
原因有以下几点:
基于深度学习的目标检测网络中,通常forground和background的region proposal数量很不均衡,负样本要比正样本多得多,这样会导致网络学习的focus被淹没;
每个样本对网络学习的贡献是不同的,学习过程中肯定出现容易和困难的样本,因此也需要网络自己去调节对他们的学习权重;
Fast R-CNN中对图像搜索出来的region proposal进行可正负样本1:3的配比,同时根据传统的hard negative mining得到了人工设置的IoU阈值0.1,去挑选负样本,虽然不是最优的方法,但是也是不能省去的部分,否则会掉点;
因此,Ross等人专门在这篇paper中探讨样本选择问题,根据模型测试样本得到的误差大小来针对所有类别的样本自动进行挖掘(loss越大说明样本对该模型越难判断),故取名”online hard example mining“。但是不同于传统机器学习,此方法在神经网络上直接实施会存在以下问题:
神经网络基于SGD随机梯度下降,在固定数据集上进行很多次迭代后才可以训练好的,如果先训练几个batch,然后froze参数,再去测试,然后挑出困难的样本,然后再去训练更新参数会大大拖慢模型产出的速度;
常规选择样本的方法是,首先将loss排序,然后选择loss比较大的一部分,其他的置0,这样就等于把其他样本认定为简单样本”丢掉了“,但是由于当时深度学习框架的限制,即使这些样本是0,但是依然占据空间,依然需要参与反向传播,并不能很好实现速加快和空间节省;
考虑到这些现实问题,作者采取了折中的方法,由于计算loss和卷积层无关,卷积层只负责提取原始图像特征,loss计算只由RoI pooling+fc层决定,所以网络在卷积之后设置了两个RoI pooling+fc层,一个只读(读所有的proposal),用于计算loss,挑选样本(样本数量为B,类似Fast R-CNN的计算方式),不梯度下降,另一个负责正常的训练,样本来自于只读网络。两个之间权重参数是共享的,整体结构如下图所示。
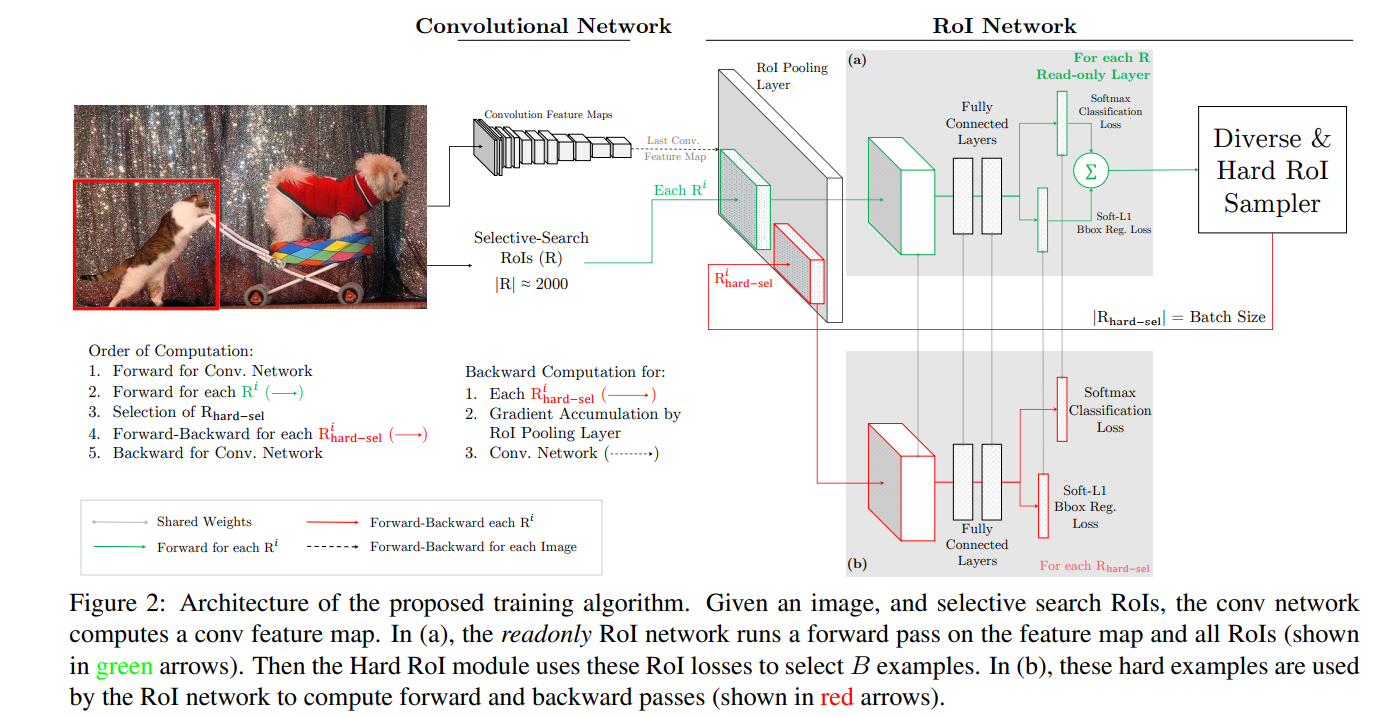
考虑到RoI中可能存在一些具有重复区域的proposal,而这些样本可能会造成相同的loss,所以如果一个是困难样本,其他的IoU比较高的重复proposal也会被选进来,造成了样本的冗余,所以不仅需要排序loss,还需要对样本进行NMS处理。
Given a list of RoIs and their losses, NMS works by iteratively selecting the RoI with the highest loss, and then removing all lower loss RoIs that have high overlap with the selected region. We use a relaxed IoU threshold of 0.7 to suppress only highly overlapping RoIs.
作者根据上述思想在Pascal VOC和COCO数据集上对了一系列对比试验,包括对比hard negative mining(原Fast R-CNN设置的阈值0.1,用于选择background),batch_size,B,以及加入了一些”bells and whistles"(多尺度和迭代式检测框回归),结果都证明OHEM的效果良好,而且也容易实现,占用空间也不会很大,在某些类别的检测上有很大的精度提升(可能每个类的学习程度也不同,可能也可以挖掘下,open problem)。
此外,作者还提到如果不去选择的话,把样本全部都倒进去,那些容易的样本的loss很低,这样的话对梯度就没什么贡献,网络应该可以自己去focus那些困难的样本。作者据此也设计了实验,对不同方法的loss做了可视化,最终发现,OHEM的效果确实最好,lower loss,higher mAP。
Discussion
OHEM是在two-stage的检测框架上提出和实现的,主要关注困难的样本,抛弃容易的样本。这种主动选择样本的方式,一方面可能间接平衡了训练的样本比例,另一方面提升了网络学习的针对性。在one -stage检测框架上提出的focal loss,也是为了处理相似的问题,通过权重分配,加大对分错样本的惩罚力度,让网络主动挖掘那些样本比例较少的类别。不过focal loss接受了所有样本,并没有完全抛弃容易的样本,而且也更加容易部署,因此两者是否可以结合,产出更有效的学习criterion,也值得去思考一下。










